Do you like AI powered, blockchain-enabled Industry 4.0 Systems. The ones that integrate artificially intelligent nodes right on the edge of the network? Or are you more motivated by the Intelligent Toaster that does it just right?
Wether you have anything to do with modern tech or not, there is no way to avoid the buzzword: A.I.
This short text is intended to give a broad and simplified view into how we tricked rocks into thinking, or pretending to think.

Our modern world is ever more governed by machines, in this intro i will try to explain how they work. Because they shape everything we see, from our social media or cars to medicine, having a basic idea of how they work is essential for a modern human.
Everyone should have at least a basic grasp at the engine that powers our way of live. Even though this intro is going to be very shallow and sometimes oversimplified it is still far better that just believing in the magic algorithms and computer gods that some people make AI out to be.
My goal in this is to make the field of AI approachable and look less like a part of the shadow realm of the nerd/geek territory and more of what it really is: some almost trivial math and a few clever ideas.
This intro to AI is going to be about systems called Neural networks, that are modeled after the human brain and how they learn new skills, it is but a small subset of the AI world but one of the simpler topics to start with.
This is going to be the top of the top of the iceberg of AI so some things are simplified and others outright ignored

Lets start somewhere simple: Cats vs. Dogs. If you have a giant list of images of cats and dogs and you want to sort them because you only like one type, you can try to do this in a few ways:
As more and more filters fail you will soon realize that there will always be a counter-example for ‘obvious’ or crude filters or the system is going to be too limited to specific edge-cases.

So why don’t we just sort a few of them by hand and get the computer to dynamically find what ‘makes’ a cat or a dog.
Imagine it like this: The computer has no damn clue what a cat or a dog is, it just randomly choses one. But then the magic happens: If it guesses correctly then tell it ‘yes, do more like that’, but if its wrong then send a negative signal so it throws away whatever idea it had used for detection.
If we transfer that system to a toddler: At first it has no clue, just like your PC. You then do your test and if it behaved correctly you reward it however appropriate, if it does something wrong you tell it to stop.
Over time the wanted behaviors will be amplified and the ‘wrong’ ones removed, just like overly strict, controlling and narcissistic parenting.
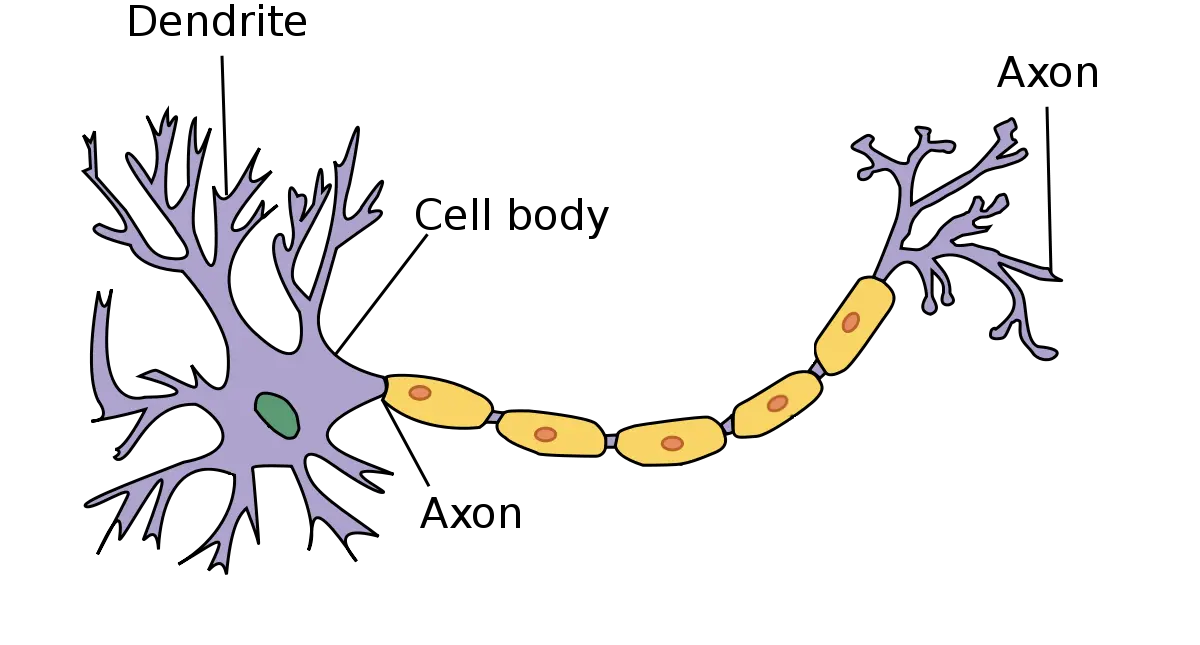
All that high level talk aside: how does one build such an artificial baby? A brain (or other neurological systems) are made of neurons, cells that consist of three parts:
They behave a bit like this: if a signal is received by the dendrites they ‘remember’ that and if enough inputs are received in a given time they fire an output-signal down their axom to other brain cells and trigger their dendrites. The fact that a cell can have multiple in and outputs allow it to do a form of simple math.
All we have to do (in theory) to get our machine-brain to work is to map this biological system to code.
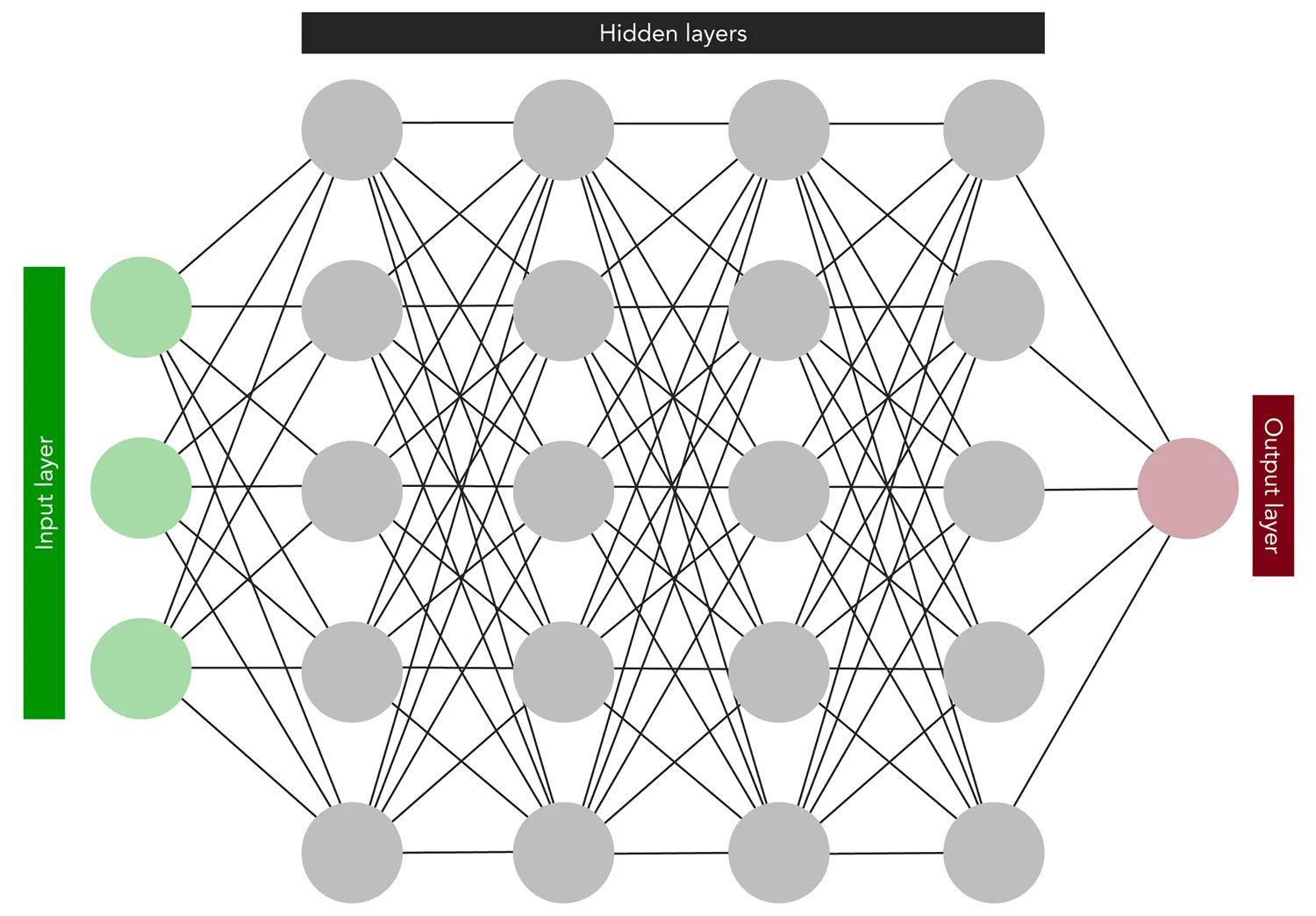
There are 2 types of Objects in our model: Nodes (Neurons) and Connections (Axoms). A connection just moves a value from one output to one input, the nodes is where the Magic happens. Our node has, just like our brain cells, inputs, activation-characteristics and outputs. The input is given by other Nodes earlier in the network, the output carries the calculated value to the next set of nodes. This is probably quite confusing so here is a visual representation of that:
The first layer that has no nodes in front is receiving our data for analysis, a bit like a neuro-link, to kickstart the action. The last layer that has no following nodes is called the output layer, this is the point where we get our cat or dog result.
The Nodes in the middle take data from their left partners, process it and feed it to their neighbors on the right. Because we don’t interact with them they are called ‘hidden neurons’ and their collective is called ‘hidden layers’.
In a perfect world we would be done here but if we were to use this thing now we would get nothing of any useful value out of it… we have to go deeper!
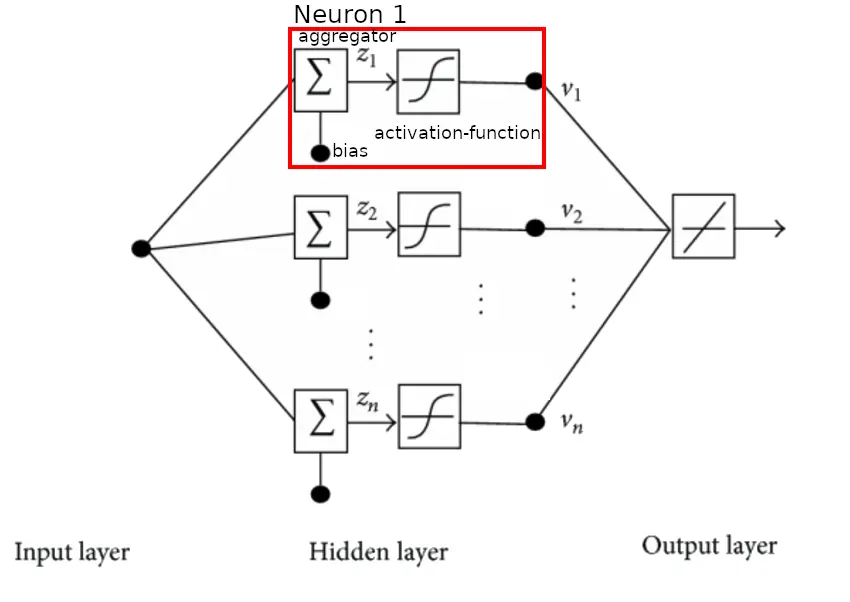
Let`s zoom in on those nodes shall we?
At it`s core a node is nothing more than a simple 1D-Math function: one value in, one out so something like:
// Linear function
f(x) = a * x
// Sigmoid function 'S'-curve
f(x) = 1 / (1 * e^(-x))
// Linear limited to -1 to +1
f(x) = clamp(-1,1,x)
// so many, many more
f(x) = ...
where the input value x is given either by previous nodes of by user input (input layer only). If there are multiple inputs they are combined into a single number by simply addin ‘em all up.
The calculated value is then adjusted by a fixed value called the ‘bias’, its just like another input but individual per node and constant. It’s named bias because it biases the number up or down depending on its value.
Now that you understand how the Nodes work lets look into the connections a bit more. A connection is more than a simple funnel from node ‘A’ node ‘B’ but it also contains a factor called a ‘weight’. the ‘heavier’ a connection is the higher the number the input is multiplied by. This allows a connection to be more or less important in the final sum giving even more nobs to tune.
// It's a linear relationship
output(input) = weight * input

We have covered pretty much all of the basics of Neural networks there is before going in deep. Recap of how an ANN (artificial-neural-network) works:
It consists of two basic building blocks: nodes and connections.
Nodes are organized into layers and connected with connections, a node can have multiple in- and outputs to communicate with other nodes. The model explained here is strictly feed forward, meaning no ‘memory’ cells and no loops or other fancy stuff.
As data flows through the network it is collected and modified by nodes and effects, depending on connection weights, the next nodes downstream.

As a start, now that our network is done we go back to nature and steal borrow some more ideas: ‘Natural selection’ and ‘Survival of the fittest’ to be exact.
To begin the training process create 100 (or however many one wants) copies of the network and just randomly set the millions of parameters. We then feed them with test cases and see how well they do (spoiler: not good) and keep the best few. We remove the rest and repopulate up to the starting amount by slightly mutating the surviving nets.
This “modify test kill reproduce”-cycle is called a “generation” because we start and end with the same amount of networks.
After 100 generations they will still be bad because this slow experimentation way takes some time to find the right path. There are some clever optimizations that can be used but we will not discuss them here.
When the training is ‘done’, meaning we stop the endless murdering, we take the best network settings we have and save them. This is now our trained model which we can use to do whatever we trained it on.
Basically all we are doing by training is trying to approximate a function that maps a gigantic input-space of millions of dimensions (input values) into a smaller output-space (possible output-categories). Thats why they are sometimes called ‘general function approximators’. The training process reduces the error between real value and ‘guess’, the longer it runs the better it gets.
 Fin.
Fin.
Congratulations you made it to the end of this little intro to AI, you can now consider yourself smarter that most others about the topic of AI and should have realized that that thing that seems magical to many is just some basic maths and clever marketing.
